What's in the .git folder
Each of the dozens of git repos on your machine contains a .git folder. But you may have never thought about the details of its contents. You know that somehow the folder holds the history of every version of every file ever committed to the repository. You just don’t know how.
The contents are less mysterious than you think. For obvious reasons, git optimizes the contents of the .git folder for size and speed. So you can’t browse into it and see your files. The object files are all named after their guid, and the data is zlib compressed. But the structure and organization is documented and understandable.
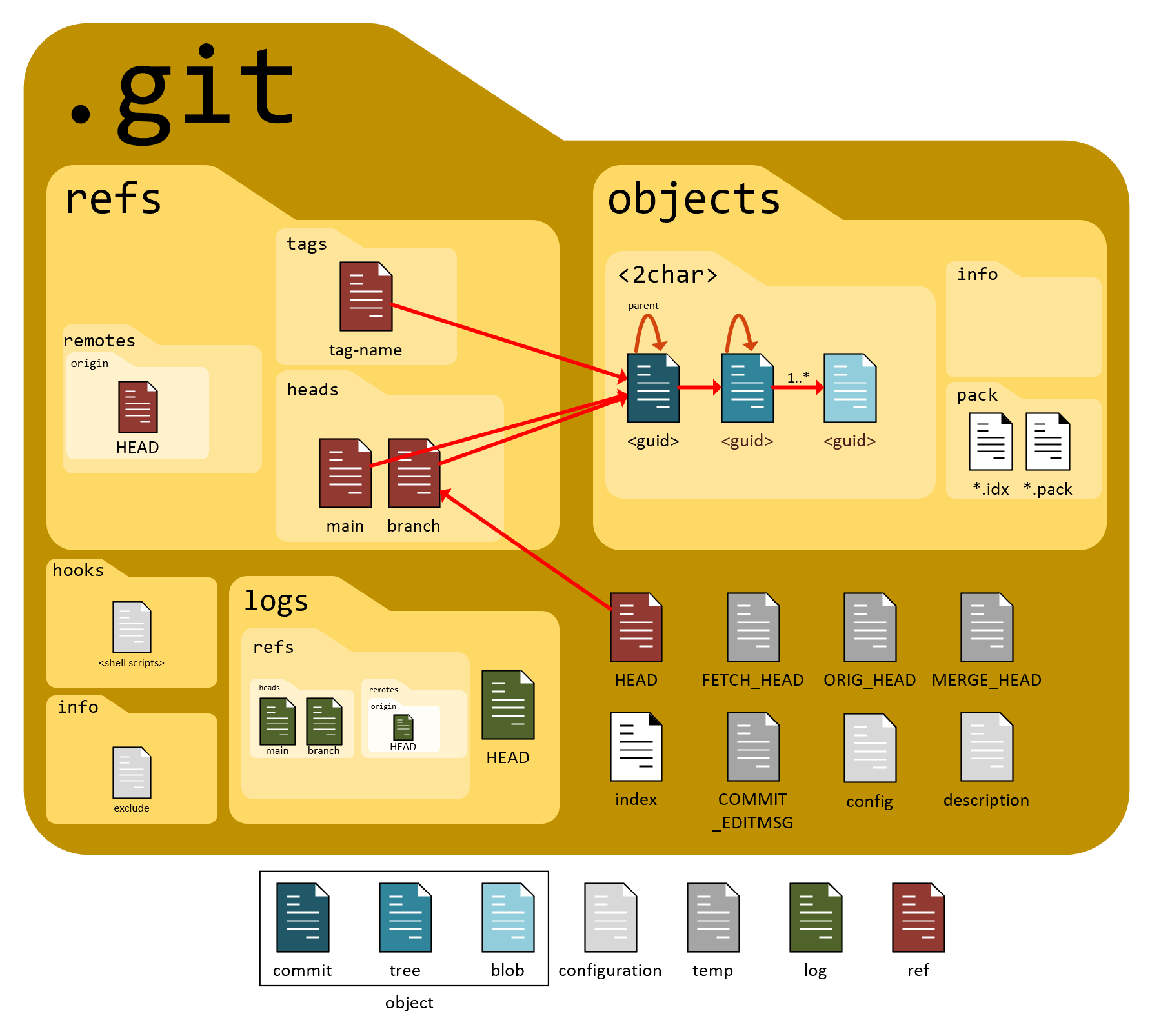
I’m not going to go into a full explanation of the files here. Others, like Rob Richardson (blog, twitter) have explained it better than I ever will. It was Rob’s talk at CodeMash that helped me understand how the contents of the .git folder worked. I just created a graphic from the info he shared. Additional details are available at GitReady.com.
I’ll simply summarize by saying that the files can be grouped into five categories:
- Objects - (blue)These represent the files and changes. Objects can be further divided into commits, trees, and blobs.
- Refs - (red)These are human-readable files that organize the objects
- Logs - (green)These are used to quickly generate logs displayed to the user.
- Config - (light gray)There are files used to config git’s behavior
- Temp - (gray)These are temporary files for information that git needs to hold between command-line actions.